

Прочитал статью про искусственный интеллект, Apple и Google. Ее написал Бенедикт Эванс — аналитик рынка мобильных устройств и сотрудник венчурного фонда Andreessen Horowitz.
Оригинал статьи: ben-evans.com
Искусственный интеллект и сбор информации
Он пишет, что за последние годы в этой индустрии произошли кардинальные сдвиги. В сторону улучшения: распознавание картинок и голосовой ввод работают практически безошибочно (с русским языком не все так хорошо).
Вы можете попросить Siri или Google Now показать фотографии вашей собаки, задать условия — только фото с пляжа, сделанные за последнюю неделю. И это сработает, покажут. Именно собаку, именно с прошлой недели, именно с пляжа. Вау, магия.
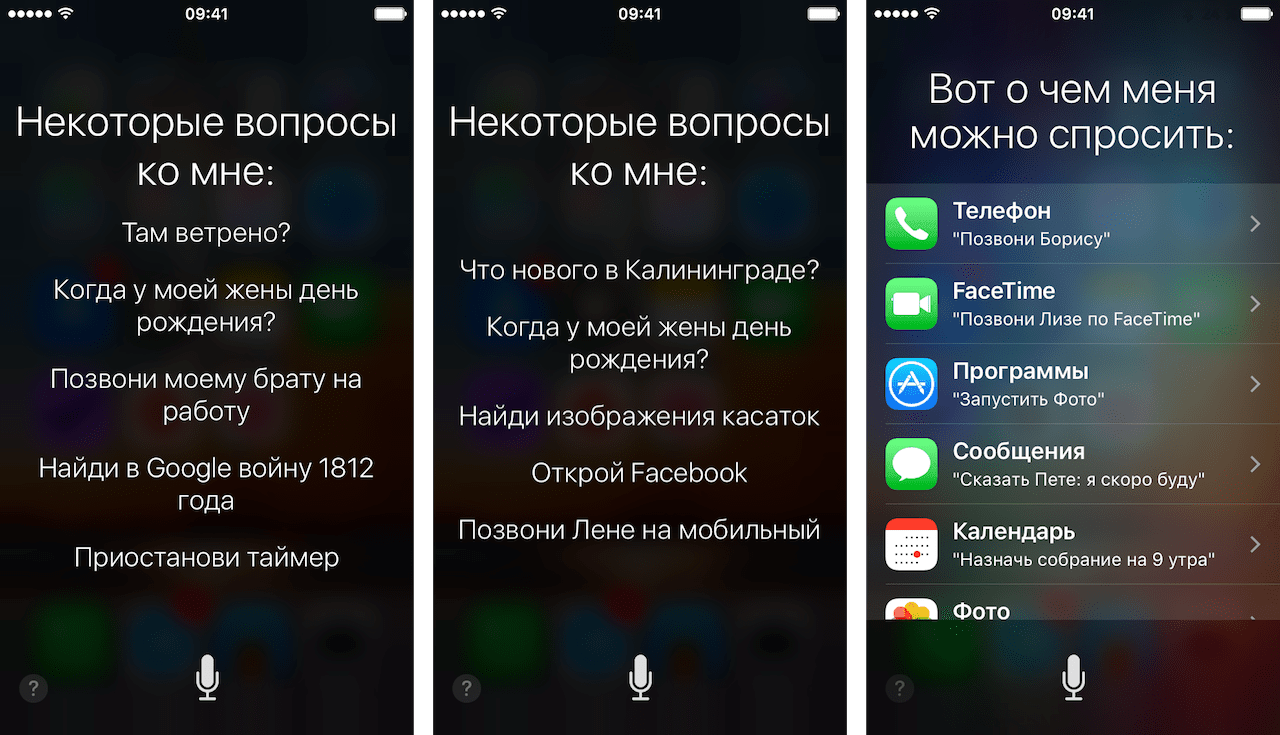
Когда вы ищете информацию с помощью голоса, то взаимодействуете с двумя разными технологиями — одна распознает голос, а другая осуществляет поисковый запрос. Объединяет их машинное обучение, которое стало сердцем обеих технологий.
Но впечатляет не то, что компьютер может найти данные на вашем компьютере, а то, что он сам научился это делать. Вы предоставляете ему доступ к миллиону картинок с пометкой «здесь есть собаки», и к миллиону — без них. Дальше он уже сам определяет, что такое собака и как она выглядит. Так вы тренируете нейронную сеть.
А теперь представьте, что это не картинки. И не собаки. Допустим, данные о безопасности сервиса или популярные среди людей статьи. Уберите обозначение, что есть что — вот разница в подходе компаний к реализации машинного обучения.
Для реализации таких функций раньше были бы нужны сотни и тысячи человеко-часов. Люди бы сидели и вручную определяли, а затем — задавали миллионы параметров, по которым компьютер должен искать данные.
Машинное обучение автоматизирует эту рутинную аналитическую работу. Оно обрабатывает не только поисковые запросы, но и результаты поисковой выдачи (и других взаимодействий пользователя с информацией), учитывает контекст запроса, ситуации, времени — все учитывает. Продвинутый поиск появился в сервисах вроде «Google Фото» именно благодаря машинному обучению.
Однако настоящая магия начнется в привычных областях: в виртуальной клавиатуре смартфона, в приложении для прослушивания музыки, в автомобиле.
И Google к этому движется. Компания повсеместно улучшает распознавание, хранение и анализ данных. Она посвятила этому практически всю конференцию Google I/O 2016.
Пользуетесь картами? Google собирает информацию. Ищете информацию в поиске? Слушаете музыку через Play Music? Пишете сообщение в Allo или Hangouts, устраиваете видеоконференцию через Duo, отвечаете на письмо в Gmail или Inbox? Верно — Google собирает информацию.
Google стремится к тому, чтобы ее продукты лучше реагировали на ваши действия. Выдавали больше контекстно-ориентированной информации, делали это точнее и быстрее. Но самое главное — чтобы сервисы Google отвечали на вопросы, на которые раньше они ответить не могли.
Apple
Тут Бенедикт Эванс переходит к Apple.
Компания всегда немного иначе относилась к современным трендам. Например, в приложении для записи дисков должна быть одна кнопка: «Прожечь». Так Стив Джобс говорил. И не важно, как это работает — не касается пользователя.
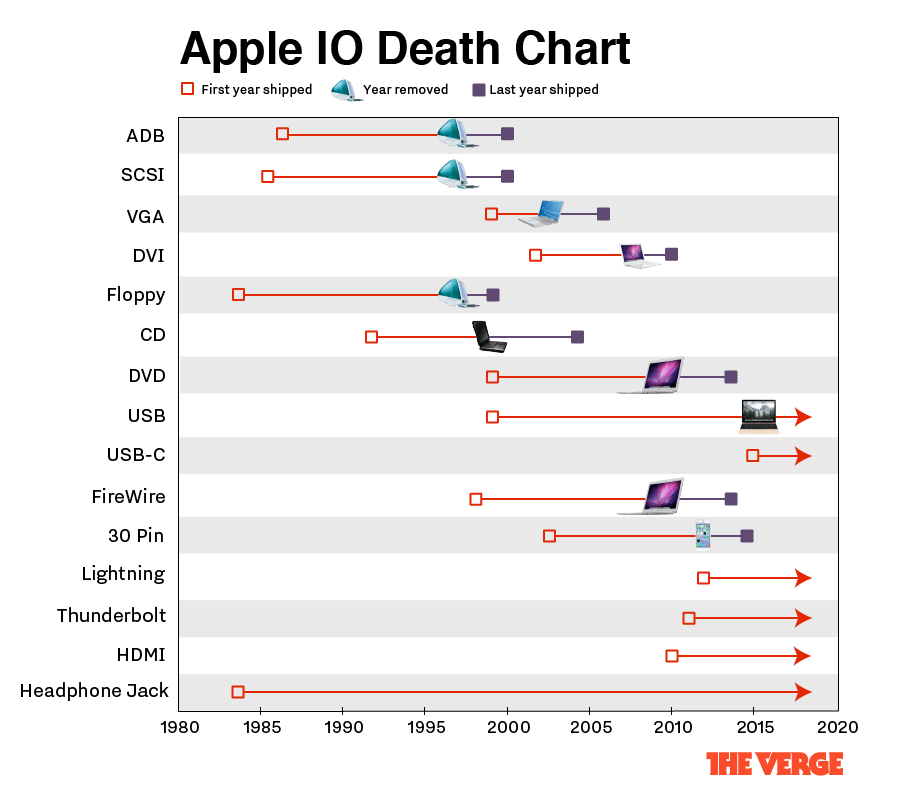
При этом Apple может легко убить популярный на рынке стандарт
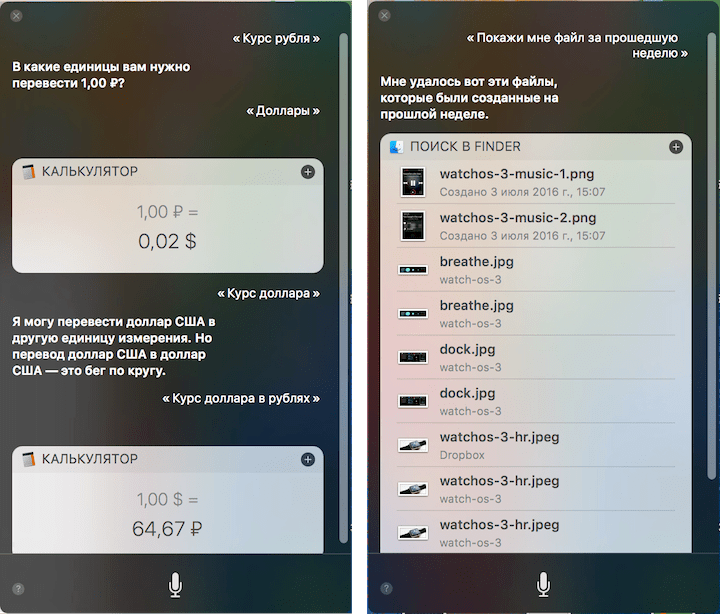
В iOS 10 компания повсеместно применяет искусственный «интеллект». Это могут быть новые функции (поиск картинок и файлов по заданным критериям), могут быть старые функции приложений (теперь они лучше работают).
Однако Apple неоднократно замечала, что не собирает пользовательские данные. Они обрабатываются и распознаются локально на устройстве. Есть исключения — например, обновленное приложение фотографий. Оно работает не в «облаке»: компания собирает минимум данных, а значит, возможности по распознаванию объектов ограничены.
Из-за локальных вычислений и отсутствия сбора пользовательских данных сервисы компании работают хуже или лучше конкурентов? Вопрос. Как будут с этими возможностями взаимодействовать другие сервисы? Вопрос. Другие приложения? Вопрос.
Хотя лица людей приложение «Фото» распознает уже сейчас, в бета-версии iOS 10 — а «облачный» сервис Google Photo до сих пор не научился этому при работе с русскими учетными записями.
Не совсем верно утверждать, что Apple не движется в этом направлении. Она снова делает это по-другому — не так, как все. Сама загнала себя в сдерживающие рамки, но мы не знаем, как именно они ограничивают (ограничивают ли?) работу сервисов и приложений компании. Главное, мы не знаем, какие сервисы обучаются, а какие — нет?
Она может и не собирать конкретно ваши данные, но изучать то, как обучались распознавать ваши данные нейронные сети.
Другие компании
Эванс пишет, что это только начало. В таком направлении движутся почти все крупные IT-компании: Microsoft, Facebook, IBM. Все компании, которые работают с «биг датой» (сбором и анализом большого количества информации).
Так, анонсированный на Google I/O 2016 голосовой ассистент Assistant радикально отличается от Google Now распознаванием логики запросов и ответной реакцией на них. Компания Amazon продвигает помощника Alexa и «умную» колонку Amazon Echo; Microsoft интегрирует Cortana в Windows, а Apple совмещает Siri и macOS.
Однако мы даже не знаем, как именно эти сервисы работают. Они действительно анализируют информацию? Они отвечают на запросы, исходя из логических пар «если, то»? Это компьютерная технология или чудо инженерной мысли?
А компьютеры уже давно не спрашивают нас — хотим ли мы выполнить действие. Но спрашивали, и это было совсем недавно. Сфера растет очень быстро, и безопасность личных данных — лишь один вопрос из огромного количества насущных тем.
Будущее
Со временем компании предоставят наборы инструкций (API) для взаимодействия с приложениями других разработчиков. Это уже сейчас происходит с Google Now, Alexa, Assistant и Siri.
Пятнадцать лет назад определение местоположения устройства по GPS-модулю было магией и уделом избранных телефонов, а сейчас это типовая функция, на которую мы не обращаем внимания. С ней взаимодействуют программы для заказа такси, Instagram, Twitter и другие социальные сети.
Но даже определение местоположения преобразится, когда искусственный интеллект и машинное обучение начнут работать на полную катушку. Они изменят работу существующих приложений. Станут такие сервисы «прослойкой» между смартфоном, приложением и ОС — или станут их неотъемлемой частью? Во втором случае дела Apple плохи.
Заключение
Бенедикт Эванс подытоживает свои мысли вопросом «что такое искусственный интеллект»?
Сейчас этот термин обозначает слишком широкий спектр компьютерных вычислений. Это противоречивая и сложная новая сфера, которая обязательно будет развиваться. Только непонятно, как именно — и непонятно, как быстро. Какие ошибки будут допущены во время ее развития? Как она повлияет на нашу жизнь? Она ее упростит или усложнит? Какие-то сферы жизни точно упростит, а на других никак не скажется.
Но сама жизнь к тому времени может измениться до неузнаваемости, и если машинное обучение разовьется, то мы привыкнем к новым возможностям. Мир представит нам новые великие компании — и преобразит уже существующие.
Ваши мысли? Стала ли сфера мобильных технологий интереснее? Видите ли вы переход от «железа» к сервисам и ПО? Будущее возбуждает, воодушевляет или угнетает вас?
P. S. Это пересказ оригинальной статьи с моими дополнениями, а не прямой перевод. Если вы знаете английский — прочитайте статью, там много дельных мыслей (которые сюда не вошли).
Заглавное изображение: [сайт калифорнийского университета в Беркли](http://scet.berkeley.edu/wp-content/uploads/Big-data.jpg)